
Lessons 10 - 14 : Pandas Primer#
This lesson is modified from Introduction to Pandas by Project Pythia, and from Exploring data using Pandas, Processing data with Pandas, Processing data with Pandas II by Geo-Python
![]()
Overview#
From the official documentation, Pandas “is a fast, powerful, flexible and easy to use open source data analysis and manipulation tool, built on top of the Python programming language.” Pandas is a powerful library for working with tabular data. You can think of it as a programmable spreadsheet. By the end of this lesson you will be able to:
install and import Pandas
import a csv file with Pandas
use Pandas for exploratory data analysis
filter and query through data to perform data analysis
Cheat Sheets#
Advanced: 2-page cheat sheet by Pandas Developers
Comprehensive: 12-page cheat sheet by Lee at Univ of Idaho
1. Installation#
If you are using anaconda, you do not need to install Pandas. If you just installed Python only, then need to install these common packages such as Pandas and numpy. You can Install panda using pip
pip install pandas
Before you type to above command in a new code cell, you can update your pip and install a dependancy.
Just run these cells one by one. After each the installation is complete, make sure to restart the kernel from the menu Kernel:Restart Kernel...
#pip install --upgrade pip
#pip install pyarrow
#pip install pandas
You need to install these once. Then you can comment the installation command (as they are already commented above) or delete these cells to avoid repeating this ever time your run this notebook.
2. Imports#
You will often see the nickname pd used as an abbreviation for Pandas in the import statement, just like numpy is often imported as np.
import pandas as pd
Note as a good coding practice, we generally import all the packages that we will need in the first cell in our notebook. However, we are importing Pandas here in the middle of our notebook for educational purpose.
3. Basic terminologies#
The Pandas DataFrame and The Pandas Series are labeled data structures.
The Pandas DataFrame (a 2-dimensional data structure) is used for storing and mainpulating table-like data (data with rows and columns) in Python. You can think of a Pandas DataFrame as a programmable spreadsheet.

The first column in dark gray, referred to as an index, contains information characterizing each row.
The first row in dark gray, referred to as header, contains the column lablels
The Pandas Series (a 1-dimensional data structure) is used for storing and manipulating a sequence of values. Pandas Series is kind of like a list, but more clever. One row or one column in a Pandas DataFrame is actually a Pandas Series.

4. Learning Pandas by an example#
Let us learn Pandas by an example. This is mainly to
gain an understanding of how to effectively use the library in your own projects
showcase the wide range of capabilities
accelerate the learning process
The idea here is to empower you to adapt these tools to various data analysis tasks.
4.1 Collecting weather data#
Let us go to NOAA to collect weather data for Fort Myers area from Jan 1, 2020 to Dec 31, 2023. Go to Browse Datasets and then select Normals Daily: Search Tool. Then make the following selections:
Select Weather Observation Type/Dataset : Daily Summaries
Select Date Range : 2020-01-01 to 2023-12-31
Search For : Cities
Enter a Search Term : Fort Myers
Then add to cart ‘Fort Myers, FL US’ and checkout your data as ‘Custom GHCN-Daily CSV’.
On your checkout select the following
Station Name
Geographic Location
Include Data Flags
Show All / Hide All | Select All / Deselect All
Precipitation
Air Temperature
Wind
Weather Type
Then submit your order. Wait for a minute or so until your data is ready. Download your data. It is always a good idea to download the data documentation to get a better understanding of your data.
4.2 Importing a csv file#
We start by reading in some data in comma-separated value (.csv) format.
Once we have a valid path to a data file that Pandas knows how to read, we can open it with:
dataframe_name = pd.read_csv('filepath/your_file.csv')
# Read a csv file with Pandas
df = pd.read_csv('3593504.csv')
4.3 Displaying a DataFrame#
4.3.1 Display DataFrame#
If you are using a Jupyter notebook, do not use print(df). Jupyter can display a nicely rendered table by just typing your dataframe_name or display(dataframename)
#Display your DataFrame
df
| STATION | NAME | LATITUDE | LONGITUDE | ELEVATION | DATE | AWND | DAPR | MDPR | PRCP | ... | TMIN | WDF2 | WDF5 | WSF2 | WSF5 | WT01 | WT02 | WT03 | WT05 | WT08 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 26.642262 | -81.848839 | 3.7 | 2020-01-01 | NaN | NaN | NaN | 0.00 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 26.642262 | -81.848839 | 3.7 | 2020-01-02 | NaN | NaN | NaN | 0.00 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 26.642262 | -81.848839 | 3.7 | 2020-01-03 | NaN | NaN | NaN | 0.00 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 26.642262 | -81.848839 | 3.7 | 2020-01-04 | NaN | NaN | NaN | 0.00 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 26.642262 | -81.848839 | 3.7 | 2020-01-05 | NaN | NaN | NaN | 0.28 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 14584 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 26.637205 | -81.877153 | 2.7 | 2023-12-27 | NaN | NaN | NaN | 0.00 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 14585 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 26.637205 | -81.877153 | 2.7 | 2023-12-28 | NaN | NaN | NaN | 0.23 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 14586 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 26.637205 | -81.877153 | 2.7 | 2023-12-29 | NaN | NaN | NaN | 0.18 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 14587 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 26.637205 | -81.877153 | 2.7 | 2023-12-30 | NaN | NaN | NaN | 0.00 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 14588 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 26.637205 | -81.877153 | 2.7 | 2023-12-31 | NaN | NaN | NaN | 0.01 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
14589 rows × 24 columns
In order to flood your screen, Jupyter did not print the whole table to screen. You can play with what you want to view. For example, try playing with these dataframe methods df.head(), df.head(3), df.tail(8)
# Show the first few columns in your DataFrame
df.head()
| STATION | NAME | LATITUDE | LONGITUDE | ELEVATION | DATE | AWND | DAPR | MDPR | PRCP | ... | TMIN | WDF2 | WDF5 | WSF2 | WSF5 | WT01 | WT02 | WT03 | WT05 | WT08 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 26.642262 | -81.848839 | 3.7 | 2020-01-01 | NaN | NaN | NaN | 0.00 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 26.642262 | -81.848839 | 3.7 | 2020-01-02 | NaN | NaN | NaN | 0.00 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 26.642262 | -81.848839 | 3.7 | 2020-01-03 | NaN | NaN | NaN | 0.00 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 26.642262 | -81.848839 | 3.7 | 2020-01-04 | NaN | NaN | NaN | 0.00 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 26.642262 | -81.848839 | 3.7 | 2020-01-05 | NaN | NaN | NaN | 0.28 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
5 rows × 24 columns
# Show the first three rows in your DataFrame
df.head(3)
| STATION | NAME | LATITUDE | LONGITUDE | ELEVATION | DATE | AWND | DAPR | MDPR | PRCP | ... | TMIN | WDF2 | WDF5 | WSF2 | WSF5 | WT01 | WT02 | WT03 | WT05 | WT08 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 26.642262 | -81.848839 | 3.7 | 2020-01-01 | NaN | NaN | NaN | 0.0 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 26.642262 | -81.848839 | 3.7 | 2020-01-02 | NaN | NaN | NaN | 0.0 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 26.642262 | -81.848839 | 3.7 | 2020-01-03 | NaN | NaN | NaN | 0.0 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
3 rows × 24 columns
#Show the last few rows in your DataFrame
df.tail(8)
| STATION | NAME | LATITUDE | LONGITUDE | ELEVATION | DATE | AWND | DAPR | MDPR | PRCP | ... | TMIN | WDF2 | WDF5 | WSF2 | WSF5 | WT01 | WT02 | WT03 | WT05 | WT08 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 14581 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 26.637205 | -81.877153 | 2.7 | 2023-12-24 | NaN | NaN | NaN | 0.00 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 14582 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 26.637205 | -81.877153 | 2.7 | 2023-12-25 | NaN | NaN | NaN | 0.00 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 14583 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 26.637205 | -81.877153 | 2.7 | 2023-12-26 | NaN | NaN | NaN | 2.72 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 14584 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 26.637205 | -81.877153 | 2.7 | 2023-12-27 | NaN | NaN | NaN | 0.00 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 14585 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 26.637205 | -81.877153 | 2.7 | 2023-12-28 | NaN | NaN | NaN | 0.23 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 14586 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 26.637205 | -81.877153 | 2.7 | 2023-12-29 | NaN | NaN | NaN | 0.18 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 14587 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 26.637205 | -81.877153 | 2.7 | 2023-12-30 | NaN | NaN | NaN | 0.00 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 14588 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 26.637205 | -81.877153 | 2.7 | 2023-12-31 | NaN | NaN | NaN | 0.01 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
8 rows × 24 columns
4.3.2 Display the size of DataFrame#
You can learn about the number of rows and column in a dataFrame using df.shape, number of rows df.shape[0] and numbers of columns df.shape[1]
#Show number of rows and columns in your DataFrame
df.shape
(14589, 24)
#Show number of rows in your DataFrame
df.shape[0]
14589
#Show number of columns in your DataFrame
df.shape[1]
24
4.3.3 Display different date types in your DataFrame#
Let’s check the datatype of columns ‘PRCP’, ‘STATION’, and ‘DATE” using df['column_label'].dtypes or df.column_label.dtypes
The data type dtype(‘O’) indicates that the Pandas column contains objects, typically strings, rather than numerical or datetime values.
#Data type for column PRCP
df['PRCP'].dtypes
dtype('float64')
#Data type for column STATION
df['STATION'].dtypes
dtype('O')
#Data type for column DATE
df.DATE.dtypes
dtype('O')
4.3.4 Change data type in your DataFrame#
Pandas did not recognize DATE as datetime format. To convert a column in a Pandas DataFrame to datetime format, you can use
df[column_name] = pd.to_datetime(column_names)
function. Here’s how you can do it:
# Convert format of DATE to datetime format
df.DATE = pd.to_datetime(df.DATE)
#Data type for column DATE
df.DATE.dtypes
dtype('<M8[ns]')
Note
Changing date types in Pandas is not uncommon because sometime Pandas cannot automatically format your data as you expect it, so you need to convert the data format manually as we did above.4.4 Filter columns by column labels#
My data has 24 columns and I want to focus only on these columns
Column Label |
Description |
|---|---|
STATION |
Station identification code (17 characters). |
NAME |
Name of the station (usually city/airport name, max 50 characters). |
DATE |
Year of the record (4 digits) followed by month (2 digits) and day (2 digits). |
PRCP |
Precipitation (mm or inches as per user preference, inches to hundredths on Daily Form pdf file) |
TMAX |
Maximum temperature (Fahrenheit or Celsius as per user preference, Fahrenheit to tenths on Daily Form pdf file) |
TMIN |
Minimum temperature (Fahrenheit or Celsius as per user preference, Fahrenheit to tenths on Daily Form pdf file) |
AWND |
Average daily wind speed (meters per second or miles per hour as per user preference) |
You can use the statement df = df[selected_columns] to select and update the DataFrame df to contain only the columns specified in the list selected_columns.
# List of column names to focus on
selected_columns = ['STATION', 'NAME', 'DATE', 'PRCP','TMAX', 'TMIN', 'AWND']
# Filter the DataFrame to include only the selected columns
df = df[selected_columns]
# Display new DataFrame
df
| STATION | NAME | DATE | PRCP | TMAX | TMIN | AWND | |
|---|---|---|---|---|---|---|---|
| 0 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 2020-01-01 | 0.00 | NaN | NaN | NaN |
| 1 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 2020-01-02 | 0.00 | NaN | NaN | NaN |
| 2 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 2020-01-03 | 0.00 | NaN | NaN | NaN |
| 3 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 2020-01-04 | 0.00 | NaN | NaN | NaN |
| 4 | US1FLLE0037 | FORT MYERS 0.8 N, FL US | 2020-01-05 | 0.28 | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 14584 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 2023-12-27 | 0.00 | NaN | NaN | NaN |
| 14585 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 2023-12-28 | 0.23 | NaN | NaN | NaN |
| 14586 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 2023-12-29 | 0.18 | NaN | NaN | NaN |
| 14587 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 2023-12-30 | 0.00 | NaN | NaN | NaN |
| 14588 | US1FLLE0072 | FORT MYERS 1.7 WNW, FL US | 2023-12-31 | 0.01 | NaN | NaN | NaN |
14589 rows × 7 columns
4.5 Filter rows by a keyword#
I only want stations at airports. You can filter a DataFrame based on whether a particular column contains a specific string using
df[column_name].str.contains(keywords)
method in Pandas.
In other words, I want to see which rows in the column df['NAME'] that contains the keyword ‘Airport’, and only retain these rows and filter out all other rows. Here is how to do this:
# Specify the keyword you want to filter for in the 'NAME' column
keyword = 'AIRPORT'
#Use Pandas method str.contains() to create a boolean mask with name 'airport_mask'
# which is `True` for rows where the `NAME` column contains the specified keyword.
airport_mask = df['NAME'].str.contains(keyword)
# Display your mask for understanding
display(airport_mask)
# Use this mask to filter the DataFrame; that is to update it with the desired condition
df = df[airport_mask]
# Print the resulting DataFrame
df
0 False
1 False
2 False
3 False
4 False
...
14584 False
14585 False
14586 False
14587 False
14588 False
Name: NAME, Length: 14589, dtype: bool
| STATION | NAME | DATE | PRCP | TMAX | TMIN | AWND | |
|---|---|---|---|---|---|---|---|
| 8216 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 2020-01-01 | 0.00 | 77.0 | 53.0 | 4.92 |
| 8217 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 2020-01-02 | 0.00 | 84.0 | 57.0 | 7.61 |
| 8218 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 2020-01-03 | 0.00 | 84.0 | 69.0 | 9.62 |
| 8219 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 2020-01-04 | 0.15 | 83.0 | 64.0 | 10.51 |
| 8220 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 2020-01-05 | 0.00 | 68.0 | 49.0 | 7.16 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 12599 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 2023-12-27 | 0.00 | 76.0 | 58.0 | 5.37 |
| 12600 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 2023-12-28 | 0.35 | 69.0 | 57.0 | 4.03 |
| 12601 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 2023-12-29 | 0.00 | 71.0 | 55.0 | 6.04 |
| 12602 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 2023-12-30 | 0.00 | 67.0 | 51.0 | 5.14 |
| 12603 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 2023-12-31 | 0.00 | 70.0 | 50.0 | NaN |
2922 rows × 7 columns
Showing unique values in a column#
How many stations do I have in that column after updating my DataFrame with that keyword?
To find unique values in a specific column, in this case, the NAME column of a DataFrame, you can use the .unique() method in Pandas.
#Display unique station names in 'NAME'
df['NAME'].unique()
array(['FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US',
'FORT MYERS PAGE FIELD AIRPORT, FL US'], dtype=object)
#Display unique station IDs in 'STATION'
df['STATION'].unique()
array(['USW00012894', 'USW00012835'], dtype=object)
4.6 Filter rows by a specific value#
If you want to filter your DataFrame to only include rows where the STATION column has the value ‘USW00012835’, you can also use boolean indexing.
df['STATION'] == 'USW00012835'
Let us do this here and let use save this a new DataFrame one_station by using .copy().
#Use Pandas create a boolean mask with name station_mask
#for all rows that the column `STAINION` has value of 'USW00012835'
station_mask = df['STATION'] == 'USW00012835'
# Use the station_mask to filter DataFrame for rows where 'Station' is 'USW00012835' and save it to a new DataFrame 'one_station'
one_station = df[station_mask].copy()
# Print the resulting DataFrame
one_station
| STATION | NAME | DATE | PRCP | TMAX | TMIN | AWND | |
|---|---|---|---|---|---|---|---|
| 11143 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 2020-01-01 | 0.00 | 78.0 | 54.0 | 4.70 |
| 11144 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 2020-01-02 | 0.00 | 85.0 | 59.0 | 7.16 |
| 11145 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 2020-01-03 | 0.00 | 86.0 | 70.0 | 8.28 |
| 11146 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 2020-01-04 | 0.17 | 82.0 | 65.0 | 10.07 |
| 11147 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 2020-01-05 | 0.00 | 70.0 | 50.0 | 8.95 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 12599 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 2023-12-27 | 0.00 | 76.0 | 58.0 | 5.37 |
| 12600 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 2023-12-28 | 0.35 | 69.0 | 57.0 | 4.03 |
| 12601 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 2023-12-29 | 0.00 | 71.0 | 55.0 | 6.04 |
| 12602 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 2023-12-30 | 0.00 | 67.0 | 51.0 | 5.14 |
| 12603 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 2023-12-31 | 0.00 | 70.0 | 50.0 | NaN |
1461 rows × 7 columns
Note
When using.copy(), you explicitly create a new DataFrame ensuring that modifications to new DataFrame do not affect the original DataFrame df. In other words, you clearly tell Pandas that you want an independent copy of the data and not just a different view.
Now I have the data for one station for my study period. While my header is informative, my index is not informative. We generally make date-time as our index as shown next.
4.7 Make a datetime column as the DataFrame index#
To make the DATE column as the index of your DataFrame, you can use:
# Note: inplace=True argument will modify the DataFrame directly, instead of creating a new one
df.set_index('Date_Column_Name',inplace=True)
However, before we set our DATE column as our index column, let us change its format to datetime format. We already did this conversion above, but let us do it again.
# Convert the "DATE" column to datetime format using pd.to_datetime()
one_station['DATE'] = pd.to_datetime(one_station['DATE'])
# Set the "DATE" column as the index of your DataFrame
one_station.set_index('DATE', inplace=True)
#Display your DataFrame with `DATE` as index
display(one_station)
| STATION | NAME | PRCP | TMAX | TMIN | AWND | |
|---|---|---|---|---|---|---|
| DATE | ||||||
| 2020-01-01 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 78.0 | 54.0 | 4.70 |
| 2020-01-02 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 85.0 | 59.0 | 7.16 |
| 2020-01-03 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 86.0 | 70.0 | 8.28 |
| 2020-01-04 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.17 | 82.0 | 65.0 | 10.07 |
| 2020-01-05 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 70.0 | 50.0 | 8.95 |
| ... | ... | ... | ... | ... | ... | ... |
| 2023-12-27 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 76.0 | 58.0 | 5.37 |
| 2023-12-28 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.35 | 69.0 | 57.0 | 4.03 |
| 2023-12-29 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 71.0 | 55.0 | 6.04 |
| 2023-12-30 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 67.0 | 51.0 | 5.14 |
| 2023-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 70.0 | 50.0 | NaN |
1461 rows × 6 columns
Note
Pandas may or may not understand the format ofDATE column as date. Thus, it is generally a good practice to convert the column to datetime format before setting it as the index, especially if you plan to perform time-based operations later on. If the column is not in datetime format, some time-related functionalities may not work correctly.
Check the index#
Now let us see how the index change of our original DataFrame df.index and the one we just modified one_station.index
#Index of the original DataFrame df
df.index
Index([ 8216, 8217, 8218, 8219, 8220, 8221, 8222, 8223, 8224, 8225,
...
12594, 12595, 12596, 12597, 12598, 12599, 12600, 12601, 12602, 12603],
dtype='int64', length=2922)
#Index of the DataFrame one_station after we changed its index to be the DATE column
one_station.index
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04',
'2020-01-05', '2020-01-06', '2020-01-07', '2020-01-08',
'2020-01-09', '2020-01-10',
...
'2023-12-22', '2023-12-23', '2023-12-24', '2023-12-25',
'2023-12-26', '2023-12-27', '2023-12-28', '2023-12-29',
'2023-12-30', '2023-12-31'],
dtype='datetime64[ns]', name='DATE', length=1461, freq=None)
You can also show the range of your index with .index.min() and .index.max() methods.
Try it out:
#print min index value in DataFrame df
print(df.index.min())
#Print max index value in DataFrame df
print(df.index.max())
#print min index value in DataFrame one_station
print(one_station.index.min())
#Print max index value in DataFrame one_station
print(one_station.index.max())
8216
12603
2020-01-01 00:00:00
2023-12-31 00:00:00
Note
You might be wondering why the index ofdf is not starting from 0. That is because we already have removed some rows from it, so the retained rows retain their original index values. If you do not want this, you can reset your index using df = df.reset_index().
Try looking at the label of column by using: one_station.columns
#Print column labels in DataFrame one_station
one_station.columns
Index(['STATION', 'NAME', 'PRCP', 'TMAX', 'TMIN', 'AWND'], dtype='object')
4.8 Descriptive statistics#
Pandas DataFrames contain useful methods for getting summary statistics. Available methods include describe(), info(), count(), mean(), median(), min(), max(), and std() (the standard deviation). You can also do column_name.describe()
#Descriptive statistics for one_station Dataframe
one_station.describe()
| PRCP | TMAX | TMIN | AWND | |
|---|---|---|---|---|
| count | 1459.000000 | 1457.000000 | 1457.000000 | 1447.000000 |
| mean | 0.156854 | 86.536719 | 68.231297 | 7.100104 |
| std | 0.456492 | 7.159212 | 8.460276 | 2.668980 |
| min | 0.000000 | 48.000000 | 35.000000 | 2.010000 |
| 25% | 0.000000 | 83.000000 | 63.000000 | 5.140000 |
| 50% | 0.000000 | 88.000000 | 70.000000 | 6.710000 |
| 75% | 0.040000 | 92.000000 | 75.000000 | 8.500000 |
| max | 4.770000 | 98.000000 | 82.000000 | 29.970000 |
You can also do it per column
#Descriptive statistics for the column 'PRCP' one_station Dataframe (dot notation)
one_station.PRCP.describe()
count 1459.000000
mean 0.156854
std 0.456492
min 0.000000
25% 0.000000
50% 0.000000
75% 0.040000
max 4.770000
Name: PRCP, dtype: float64
You can also use dic notation one_station['PRCP'] instead of dot notation one_station.PRCP.
#Descriptive statistics for the column 'PRCP' one_station Dataframe (dic notation)
one_station['PRCP'].describe()
count 1459.000000
mean 0.156854
std 0.456492
min 0.000000
25% 0.000000
50% 0.000000
75% 0.040000
max 4.770000
Name: PRCP, dtype: float64
Note
The dot notation will not work if the column name is not a valid variable name (e.g., having space, starting with a number, etc.).You can do it per a group of columns
# List of columns to show
columns_group = ['PRCP', 'AWND']
#Descriptive statistics for a selected columns in one_station Dataframe
one_station[columns_group].describe()
| PRCP | AWND | |
|---|---|---|
| count | 1459.000000 | 1447.000000 |
| mean | 0.156854 | 7.100104 |
| std | 0.456492 | 2.668980 |
| min | 0.000000 | 2.010000 |
| 25% | 0.000000 | 5.140000 |
| 50% | 0.000000 | 6.710000 |
| 75% | 0.040000 | 8.500000 |
| max | 4.770000 | 29.970000 |
4.9 Resampling of time-series data#
Remember Pandas is powerful because it is a programmable spreadsheet. For example, can to find the min, max, mean, or median value per month, week, year, or any other criteria. You can use the method of
df.resample("Freqency").arreegation_method()
Frequency: The target frequency you want to resample to. Pandas supports many frequencies:
“D” - Calender day
“B” - Business day
“M” - Monthly frequency
“W” - Weekly frequency
“h” - Hourly frequency
“min” - Minutely frequency
and many more as shown in Pandas documentation.
Aggregation Methods: When downsampling, you often want to summarize groups of data using Pandas provided methods such as:
mean()- Calculates the meansum()- Calculates the summin()- Finds the minimum valuemax()- Finds the maximum valuestd()- Calculates standard deviation
… and others
For example, find the max PRCP, TMAX, TMIN and AWND for each week in your dataset
#Max PRCP, TMAX, TMIN and AWND in every week of my dataset using .resample() method
one_station.resample("W").max()
| STATION | NAME | PRCP | TMAX | TMIN | AWND | |
|---|---|---|---|---|---|---|
| DATE | ||||||
| 2020-01-05 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.17 | 86.0 | 70.0 | 10.07 |
| 2020-01-12 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 88.0 | 70.0 | 11.63 |
| 2020-01-19 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 85.0 | 68.0 | 10.07 |
| 2020-01-26 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 79.0 | 61.0 | 14.09 |
| 2020-02-02 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.47 | 78.0 | 60.0 | 9.17 |
| ... | ... | ... | ... | ... | ... | ... |
| 2023-12-03 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 86.0 | 71.0 | 9.40 |
| 2023-12-10 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.18 | 84.0 | 68.0 | 10.07 |
| 2023-12-17 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 1.23 | 77.0 | 68.0 | 15.66 |
| 2023-12-24 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 78.0 | 59.0 | 10.51 |
| 2023-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 2.01 | 80.0 | 67.0 | 8.50 |
209 rows × 6 columns
Find the min PRCP, TMAX, TMIN and AWND in each year in my dataset
#Min PRCP, TMAX, TMIN and AWND in each year .resample() method
one_station.resample("Y").min()
C:\Users\aelshall\AppData\Local\Temp\ipykernel_3728\152910108.py:2: FutureWarning: 'Y' is deprecated and will be removed in a future version, please use 'YE' instead.
one_station.resample("Y").min()
| STATION | NAME | PRCP | TMAX | TMIN | AWND | |
|---|---|---|---|---|---|---|
| DATE | ||||||
| 2020-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 59.0 | 37.0 | 2.01 |
| 2021-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 61.0 | 41.0 | 2.24 |
| 2022-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 48.0 | 35.0 | 2.46 |
| 2023-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 62.0 | 40.0 | 2.68 |
This is mainly a quick overview on .resample() method. To learn this method in details, check Pandas user-guide on resampling.
4.10 Groupby#
While resample is specifically designed to change the frequency of the time series, groupby is a more general-purpose tool for grouping data based on some criteria, which can include time-related criteria but is not limited to time-series data. It can be used with any categorical or numerical criteria for grouping. It’s more flexible and allows for custom aggregation functions.
4.10.1 Groupby for categorical data#
For example, what if we want to find the monthly mean of TMAX and TMIN for the two weather stations at two airports. Let us first create the DataFrame two_stations for these two weather stations.
#Create a new DataFrame contains only stations at airports
two_stations = df.copy()
# Convert the "DATE" column to datetime format
two_stations['DATE'] = pd.to_datetime(two_stations['DATE'])
# Set the "DATE" column as the index of your DataFrame
two_stations.set_index('DATE', inplace=True)
#Display data for two stations
two_stations
| STATION | NAME | PRCP | TMAX | TMIN | AWND | |
|---|---|---|---|---|---|---|
| DATE | ||||||
| 2020-01-01 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.00 | 77.0 | 53.0 | 4.92 |
| 2020-01-02 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.00 | 84.0 | 57.0 | 7.61 |
| 2020-01-03 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.00 | 84.0 | 69.0 | 9.62 |
| 2020-01-04 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.15 | 83.0 | 64.0 | 10.51 |
| 2020-01-05 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.00 | 68.0 | 49.0 | 7.16 |
| ... | ... | ... | ... | ... | ... | ... |
| 2023-12-27 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 76.0 | 58.0 | 5.37 |
| 2023-12-28 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.35 | 69.0 | 57.0 | 4.03 |
| 2023-12-29 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 71.0 | 55.0 | 6.04 |
| 2023-12-30 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 67.0 | 51.0 | 5.14 |
| 2023-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 70.0 | 50.0 | NaN |
2922 rows × 6 columns
We can see that we have two stations “USW00012894” and “USW00012835”.
We can to find the monthly mean of our data. However, if you tried to apply a method such as mean() or resample() as we did before in Secion 4.9 you will get an error
TypeError: agg function failed [how->mean,dtype->object]
suggesting that that you have non-numeric columns in your DataFrame, and the mean() operation is not applicable to those columns.
#This commented code will give you an error because two_stations has non-numeric data
#two_stations.mean()
Note
In case you are wonder, why did the.mean() method worked with the one_station DataFrame, but not with two_stations DataFrame even although the one_station also contained non-numeric values in columns NAME and STATION? In one_station DataFrame the values in non-numeric columns were not changing because it is only one station. But with two_stations DataFrame the values in the non-numeric columns NAME and STATION are chaning because we have two stations. Thus, we cannot apply the .mean() method. In other words, what is the mean of "USW00012894" and "USW00012835" ?
Thus, before using resample() and mean(), it’s a good idea to ensure that all columns you’re aggregating are numeric.
Let us filter out STATION and NAME that are the non-numeric columns, and only keep the numeric columns that are PRCP, TMAX, TMIN, and AWND. For filtering out, you can do two_stations[columns_to_keep] as we learned before in Section 4.4. Then we can apply the .mean() , .resample('Y').mean() , or whatever method you need to use.
#Select the numeric columns that you want
columns_to_keep = ['PRCP', 'TMAX', 'TMIN', 'AWND']
#Apply mean to numeric columns
two_stations[columns_to_keep].resample('Y').mean()
C:\Users\aelshall\AppData\Local\Temp\ipykernel_3728\1940048899.py:5: FutureWarning: 'Y' is deprecated and will be removed in a future version, please use 'YE' instead.
two_stations[columns_to_keep].resample('Y').mean()
| PRCP | TMAX | TMIN | AWND | |
|---|---|---|---|---|
| DATE | ||||
| 2020-12-31 | 0.149454 | 85.946721 | 67.554036 | 7.337937 |
| 2021-12-31 | 0.130947 | 85.502740 | 66.902740 | 6.733370 |
| 2022-12-31 | 0.187269 | 86.472452 | 67.749311 | 6.953064 |
| 2023-12-31 | 0.126401 | 86.517808 | 68.080822 | 7.132926 |
The above method works, but using
df.groupby(groupby_column)[columns_to_show].method_you_need()
can be more pwoerful because it will show you these values for each category, which is in that case for each station.
#Select columns only
columns_to_keep = ['PRCP', 'TMAX', 'TMIN', 'AWND']
# For the two_stations DataFrame group by 'STATION' then apply .resample('Y').mean() to the selected columns only
# groupy-> Select columns -> apply method
two_stations.groupby(['STATION'])[columns_to_keep].resample('Y').mean()
C:\Users\aelshall\AppData\Local\Temp\ipykernel_3728\579840131.py:6: FutureWarning: 'Y' is deprecated and will be removed in a future version, please use 'YE' instead.
two_stations.groupby(['STATION'])[columns_to_keep].resample('Y').mean()
| PRCP | TMAX | TMIN | AWND | ||
|---|---|---|---|---|---|
| STATION | DATE | ||||
| USW00012835 | 2020-12-31 | 0.156913 | 86.120219 | 68.005464 | 7.369235 |
| 2021-12-31 | 0.148301 | 86.112329 | 67.654795 | 6.754658 | |
| 2022-12-31 | 0.192775 | 86.808864 | 68.307479 | 6.998244 | |
| 2023-12-31 | 0.129451 | 87.109589 | 68.958904 | 7.275152 | |
| USW00012894 | 2020-12-31 | 0.141995 | 85.773224 | 67.101370 | 7.306639 |
| 2021-12-31 | 0.113544 | 84.893151 | 66.150685 | 6.712082 | |
| 2022-12-31 | 0.181717 | 86.139726 | 67.197260 | 6.909370 | |
| 2023-12-31 | 0.123352 | 85.926027 | 67.202740 | 6.991479 |
Try to do it again, but this time groupby ‘NAME` or both of them.
#Select columns only
columns_to_keep = ['PRCP', 'TMAX', 'TMIN', 'AWND']
# For the two_stations DataFrame group by 'STATION' then apply .resample('Y').mean() to the selected columns only
# groupy-> Select columns -> apply method
two_stations.groupby(['NAME'])[columns_to_keep].resample('Y').mean()
C:\Users\aelshall\AppData\Local\Temp\ipykernel_3728\1860762282.py:6: FutureWarning: 'Y' is deprecated and will be removed in a future version, please use 'YE' instead.
two_stations.groupby(['NAME'])[columns_to_keep].resample('Y').mean()
| PRCP | TMAX | TMIN | AWND | ||
|---|---|---|---|---|---|
| NAME | DATE | ||||
| FORT MYERS PAGE FIELD AIRPORT, FL US | 2020-12-31 | 0.156913 | 86.120219 | 68.005464 | 7.369235 |
| 2021-12-31 | 0.148301 | 86.112329 | 67.654795 | 6.754658 | |
| 2022-12-31 | 0.192775 | 86.808864 | 68.307479 | 6.998244 | |
| 2023-12-31 | 0.129451 | 87.109589 | 68.958904 | 7.275152 | |
| FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 2020-12-31 | 0.141995 | 85.773224 | 67.101370 | 7.306639 |
| 2021-12-31 | 0.113544 | 84.893151 | 66.150685 | 6.712082 | |
| 2022-12-31 | 0.181717 | 86.139726 | 67.197260 | 6.909370 | |
| 2023-12-31 | 0.123352 | 85.926027 | 67.202740 | 6.991479 |
4.11 Slicing with loc and iloc#
Slicing is a method used to extract a subset of data from a larger data structure, such as a list, array, or DataFrame, by specifying a range or specific indices.ases.
The following two ways to access data are preferred by Pandas over other methods:
For
.loc["row_start":"row_end", "col_start":"col_end"]:.loc[]: Access data by label."row_start":"row_end": Specify the range of rows by their labels, inclusively."col_start":"col_end": Specify the range of columns by their labels, inclusively.
For
.iloc[row_start:row_end, col_start:col_end]:.iloc[]: Access data by index position.row_start:row_end: Specify the range of rows by their index positions, exclusively.col_start:col_end: Specify the range of columns by their index positions, exclusively.
The .loc[] method when accessing data by label is inclusive, meaning it includes the specified start and end labels.
The iloc[] method when accessing data by index is exclusive, meaning it includes the start index but excludes the end index.
The above is a general syntax, but there are some many special cases.ases.
4.11.1 Slicing with loc#
Let us slice from index label 2023-12-30 to 2023-12-31 and column labels STATION to PRCP.
Note
In Pandas, to perform a value-based partial slicing operation, your DataFrame index need to sorted in ascending order. You can do this using.sort_index(inplace=True).
# Sort the two_stations DataFrame by the 'DATE' index in ascending order
two_stations.sort_index(inplace=True)
# View last 5 rows in two_stations DataFrame
display(two_stations.tail(5))
# View slice from '2023-12-30' to'2023-12-31', and 'from STATION' to 'PRCP' using loc (inclusive)
display(two_stations.loc['2023-12-30':'2023-12-31', 'STATION':'PRCP'])
| STATION | NAME | PRCP | TMAX | TMIN | AWND | |
|---|---|---|---|---|---|---|
| DATE | ||||||
| 2023-12-29 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 70.0 | 54.0 | 4.92 |
| 2023-12-30 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 67.0 | 51.0 | 5.14 |
| 2023-12-30 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 66.0 | 51.0 | 4.70 |
| 2023-12-31 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 69.0 | 48.0 | 2.01 |
| 2023-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 70.0 | 50.0 | NaN |
| STATION | NAME | PRCP | |
|---|---|---|---|
| DATE | |||
| 2023-12-30 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 |
| 2023-12-30 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 |
| 2023-12-31 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 |
| 2023-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 |
You can also do '2023-12:30': to retrieve all rows from the specified start date 2023-12-30 to the end of the last row. You can also do the same for columns 'STATION': if needed.
# In two_stations DataFrame, view slice from '2023-12-30' to the last row, and 'from STATION' to the last column using loc
display(two_stations.loc['2023-12-30':, 'STATION':])
| STATION | NAME | PRCP | TMAX | TMIN | AWND | |
|---|---|---|---|---|---|---|
| DATE | ||||||
| 2023-12-30 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 67.0 | 51.0 | 5.14 |
| 2023-12-30 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 66.0 | 51.0 | 4.70 |
| 2023-12-31 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 69.0 | 48.0 | 2.01 |
| 2023-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 70.0 | 50.0 | NaN |
You can also specify what you exactly ['NAME','STATION','PRCP'] need instead of having a range.
# In two_stations DataFrame, view slice from '2023-12-30' to the last row, and for clumns 'NAME','STATION', and'PRCP' in that order
display(two_stations.loc['2023-12-30':, ['NAME','STATION','PRCP']])
| NAME | STATION | PRCP | |
|---|---|---|---|
| DATE | |||
| 2023-12-30 | FORT MYERS PAGE FIELD AIRPORT, FL US | USW00012835 | 0.0 |
| 2023-12-30 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | USW00012894 | 0.0 |
| 2023-12-31 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | USW00012894 | 0.0 |
| 2023-12-31 | FORT MYERS PAGE FIELD AIRPORT, FL US | USW00012835 | 0.0 |
Special case for a datetime index#
If your index is datetime you can even do more, like slicing a certain year.
For example let us say I want to slice the data of 2023. It is very simple .loc['2023']
#Slice 2023 data in two_stations DataFrame using .loc[]
two_stations.loc['2023']
| STATION | NAME | PRCP | TMAX | TMIN | AWND | |
|---|---|---|---|---|---|---|
| DATE | ||||||
| 2023-01-01 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 87.0 | 67.0 | 3.13 |
| 2023-01-01 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 86.0 | 67.0 | 2.91 |
| 2023-01-02 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 87.0 | 67.0 | 6.49 |
| 2023-01-02 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 85.0 | 65.0 | 6.26 |
| 2023-01-03 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 86.0 | 66.0 | 6.93 |
| ... | ... | ... | ... | ... | ... | ... |
| 2023-12-29 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 70.0 | 54.0 | 4.92 |
| 2023-12-30 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 67.0 | 51.0 | 5.14 |
| 2023-12-30 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 66.0 | 51.0 | 4.70 |
| 2023-12-31 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 69.0 | 48.0 | 2.01 |
| 2023-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 70.0 | 50.0 | NaN |
730 rows × 6 columns
4.11.2 Slicing with iloc#
Do the same with iloc, and slice from rows 2023-12-30 to 2023-12-31 and columns STATION to PRCP.
First find the shape of this DataFrame to get an idea about the index number for the last four rows.
#Find the shape of two_stations DataFrame first
two_stations.shape
(2922, 6)
# View slice from '2023-12-30' to'2023-12-31', and 'from STATION' to 'PRCP' using iloc (exclusive)
display(two_stations.iloc[2918:2922, 0:3])
| STATION | NAME | PRCP | |
|---|---|---|---|
| DATE | |||
| 2023-12-30 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 |
| 2023-12-30 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 |
| 2023-12-31 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 |
| 2023-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 |
You can also do 2918: to retrieve all rows from the specified index to the end of the last index.
# View slice from '2023-12-30' to the last row, and from 'STATION' to the last column using iloc (exclusive)
display(two_stations.iloc[2918:, 0:])
| STATION | NAME | PRCP | TMAX | TMIN | AWND | |
|---|---|---|---|---|---|---|
| DATE | ||||||
| 2023-12-30 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 67.0 | 51.0 | 5.14 |
| 2023-12-30 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 66.0 | 51.0 | 4.70 |
| 2023-12-31 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 69.0 | 48.0 | 2.01 |
| 2023-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 70.0 | 50.0 | NaN |
In the above example, since you are starting from index 0 you can just do : which will select all columns.
# View slice from '2023-12-30' to the last row, and from 'STATION' to the last column using iloc (exclusive)
display(two_stations.iloc[2918:, :])
| STATION | NAME | PRCP | TMAX | TMIN | AWND | |
|---|---|---|---|---|---|---|
| DATE | ||||||
| 2023-12-30 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 67.0 | 51.0 | 5.14 |
| 2023-12-30 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 66.0 | 51.0 | 4.70 |
| 2023-12-31 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 69.0 | 48.0 | 2.01 |
| 2023-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 70.0 | 50.0 | NaN |
There are so many ways for slicing through a DataFrame. For more examples and details, check Introduction to Pandas by Project Pythia.
4.12 Dicing#
While slicing involves selecting specific rows and columns based on their indices or labels, dicing goes a step further by selecting specific elements based on some condition or criteria. It looks something like this
# for one condition and multiple columns to show
df.loc[condtion_on_row, columns_to_show]
# for multiple conditions and multiple columns to show
df.loc[(condtion_on_row) & (condtion_on_row), columns_to_show]
You can replace & by any other logical operator such as <,<=, >,>=, !=, ==, |.
Let us do a simple example investigating extreme values. Find the days where 'TMIN'<=36
#Condition 'TMIN'<=36 (dot notation)
condition= two_stations.TMIN<=36
#Retriving all data with the above condition
two_stations.loc[condition]
| STATION | NAME | PRCP | TMAX | TMIN | AWND | |
|---|---|---|---|---|---|---|
| DATE | ||||||
| 2020-01-22 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 61.0 | 35.0 | 10.29 |
| 2022-01-24 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 66.0 | 36.0 | 3.58 |
| 2022-01-30 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 60.0 | 35.0 | 5.59 |
| 2022-01-30 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.0 | 62.0 | 35.0 | 6.93 |
| 2022-01-31 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.0 | 70.0 | 36.0 | 5.14 |
What we did in the above example, is a mask with a condition that returns Boolean value True when the condition is met and False otherwise.
Now let us do another extreme values by have two conditions: 'PRCP'>0 and 'TMAX'>=98
#Coditions of 'PRCP'>0 and 'TMAX'>98 (dot notation)
conditions= (two_stations.PRCP>0) & (two_stations.TMAX>=98)
#Retriving all data with the above condtions
two_stations.loc[conditions]
| STATION | NAME | PRCP | TMAX | TMIN | AWND | |
|---|---|---|---|---|---|---|
| DATE | ||||||
| 2020-07-31 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.01 | 98.0 | 77.0 | 5.14 |
| 2022-08-22 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 1.11 | 98.0 | 76.0 | 5.82 |
One more argument ["column_to_select1", "column_to_select2", ...] are the columns that you want retrive. For example, suppose we want to know the wwind speed and Station ID when these two conditions ‘PRCP’>0 and ‘TMAX’>80 are meet.
# Coditions of 'PRCP'>0 and 'TMAX'>98 (dot notation)
conditions= (two_stations.PRCP>0) & (two_stations.TMAX>=98)
# Columns to show
columns_to_show = ['AWND','STATION']
#Retriving all data with the above condtions and showing selectec columns
two_stations.loc[conditions, columns_to_show ]
| AWND | STATION | |
|---|---|---|
| DATE | ||
| 2020-07-31 | 5.14 | USW00012894 |
| 2022-08-22 | 5.82 | USW00012894 |
In the above examples, we used dot notation, but we can also use dic notation. Check Section 4.8 for more information about the difference between dot and doc notations.
# Coditions of 'PRCP'>0 and 'TMAX'>98 (dic notation)
conditions= (two_stations['PRCP']>0) & (two_stations['TMAX']>=98)
# Columns to show
columns_to_show = ['AWND','STATION']
#Retriving all data with the above condtions and showing selectec columns
two_stations.loc[conditions, columns_to_show ]
| AWND | STATION | |
|---|---|---|
| DATE | ||
| 2020-07-31 | 5.14 | USW00012894 |
| 2022-08-22 | 5.82 | USW00012894 |
4.13 Slicing and dicing together#
You can first slice and then dice and vice verse using chain method. For example, df.loc[dice].loc[slice].
For example, retrive wind and station data with 'TMAX'>=96 and 'PRCP'>0 in 2023.
#conditions of 'PRCP'>0 and 'TMAX'>=96
conditions= (two_stations["PRCP"] > 0) & (two_stations["TMAX"]>=96)
#columns to show
columns_to_show= ['STATION','AWND']
# Dice to my condition and columns to show -> slice to 2023 that is from '2023-01-01' to '2023-12-31'
two_stations.loc[conditions, columns_to_show].loc['2023-01-01':'2023-12-31']
| STATION | AWND | |
|---|---|---|
| DATE | ||
| 2023-07-04 | USW00012835 | 3.58 |
| 2023-07-20 | USW00012835 | 5.14 |
| 2023-07-21 | USW00012835 | 4.25 |
| 2023-08-12 | USW00012894 | 4.03 |
| 2023-08-12 | USW00012835 | 3.80 |
| 2023-08-15 | USW00012835 | 4.03 |
Challange your understanding#
Find the mean wind speed when 'TMAX'>=96 and 'PRCP'>0 in 2023. This is the same as the above example. But then you need to select column AWND using .AWMD, ['AWND'] , or .loc[:,'AWND'].Then do one more chain with the .mean() method.
#conditions of 'PRCP'>0 and 'TMAX'>=96
conditions= (two_stations["PRCP"] > 0) & (two_stations["TMAX"]>=96)
#columns to show
columns_to_show= ['STATION','AWND']
# Approach 1
# Dice to my condition and columns to show -> slice to 2023
# -> select AWMD column -> use mean() method
two_stations.loc[conditions, columns_to_show].loc['2023-01-01':'2023-12-31'].AWND.mean()
np.float64(4.138333333333334)
You can also try the two other indexing approaches suggested above
# Approach 2
# Dice to my condition and columns to show -> slice to 2023
# -> index to AWMD column -> use mean() method
two_stations.loc[conditions, columns_to_show].loc['2023-01-01':'2023-12-31']['AWND'].mean()
np.float64(4.138333333333334)
# Approach 3
# Dice to my condition and columns to show -> slice to 2023
# -> index to AWMD column -> use mean() method
two_stations.loc[conditions, columns_to_show].loc['2023-01-01':'2023-12-31'].loc[:,'AWND'].mean()
np.float64(4.138333333333334)
Ask a LLM (opitional)#
Below are three approaches for finding the mean AWMD for the extrem conditions PRCP> 0 and TMAX>=96 in 2023. Ask a LLM if there are other approaches to find that mean. Here is the prompt that I provided:
Below are three approaches to find that mean of AWND. Can you suggest another approach?
```Python
#conditions of 'PRCP'>0 and 'TMAX'>=96
conditions= (two_stations["PRCP"] > 0) & (two_stations["TMAX"]>=96)
#columns to show
columns_to_show= ['STATION','AWND']
# Approach 1
# Dice to my condition and columns to show -> slice to 2023
# -> index to AWMD column -> use mean() method
two_stations.loc[conditions, columns_to_show].loc['2023-01-01':'2023-12-31'].AWND.mean()
# Approach 2
# Dice to my condition and columns to show -> slice to 2023
# -> index to AWMD column -> use mean() method
two_stations.loc[conditions, columns_to_show].loc['2023-01-01':'2023-12-31']['AWND'].mean()
#Approach 3
# Dice to my condition and columns to show -> slice to 2023
# -> index to AWMD column -> use mean() method
two_stations.loc[conditions, columns_to_show].loc['2023-01-01':'2023-12-31'].loc[:,'AWND'].mean()
```
I am writing in Jupyter notebook using the Python 3 (system-wide) kernel.
I provided the above prompt to ChatGPT 3.5. Here are the responses that I got:
ChatGPT 3.5, provided an approach to filter the data and calculate the mean, and suggested to “choose the method that best fits your coding style and preference.”
# Approach 4
# Use loc to apply conditions, slice to 2023, select the 'AWND' column, and calculate the mean directly
two_stations.loc[conditions & (two_stations.index.year == 2023), 'AWND'].mean()
np.float64(4.138333333333334)
ChatGPT suggested subsetting using Datetime column .index.year. This is what we will learn next. However, you can ask your LLM to explain the solution to you.
4.14 Subsetting using Datetime Column#
Slicing as shown in Section 4.11 is a useful technique for subsetting a DataFrame, but there are also other options that can be equally useful.
Before we start, let us first create a fresh copy of our DataFrame, just to review and remember what we did before.
#Create a new DataFrame contains only stations at airports
two_stations = df.copy()
# Convert the "DATE" column to datetime format
two_stations['DATE'] = pd.to_datetime(two_stations['DATE'])
# Set the "DATE" column as the index of your DataFrame
two_stations.set_index('DATE', inplace=True)
If your DataFrame uses datetime values for indices, you can select data from only one day using df.index.day, one month using df.index.month, one year using df.index.year, and so on.
For example, the expression
two_stations.index.month == 12
will create a boolean mask where each element corresponds to whether the month component of the index of each row is equal to 12. In other words, this expression give True for rows where the month is December (i.e., month number 12) and False for rows where the month is not December. This boolean mask can then be used to filter rows based on the condition that the month is December using for example,
df.loc([two_stations.index.month == 12])
Let us say that we want to calculate the mean of the TMIN and TMAX columns for the month of December across all years for ourtwo_stations DataFrame. How to approach this task? Here is one strategy
Filter the rows of the
two_stationsDataFrame based on the condition of the month of December as described aboveSelect the columns
TMINandTMAXfrom the DataFrame using[['TMIN','TMAX']], or.loc[:, ['TMIN','TMAX']]Apply
.mean()function to the filtered DataFrame
You can also do step 2 column selection before step 1 filtering by month using datetime subset.
Let us try to test both of them:
# Approach 1 Datetime subset -> Select
#Subset condition with datetime index: month == 12 (December)
condition = two_stations.index.month == 12
#Subset given my condition -> select columns .loc[:,['TMIN','TMAX']]-> apply .mean() function
two_stations.loc[condition,:].loc[:,['TMIN','TMAX']].mean()
TMIN 58.584677
TMAX 77.197581
dtype: float64
Test your understanding#
Redo the above example, but by applying step 2 that is column selections, before step 1 that is filtering for the month of december.
# Approach 2 Select -> Datetime subset
#Subset condition with datetime index is the month == 12 (December)
condition = two_stations.index.month == 12
# Select columns .loc[:,['TMIN','TMAX']] -> Subset given my condition -> apply .mean() function
two_stations.loc[:,['TMIN','TMAX']].loc[condition,:].mean()
TMIN 58.584677
TMAX 77.197581
dtype: float64
Another example with LLM (opitional)#
Do a for loop to find the mean TMIN and TMAX from Jan to Dec from 2020-01-01 to 2023-12-31. For each iteration print month, TMIN, and TMAX in a table format. To print in table format you can use install the package tabulate that can do this for you. We did not learn this package, but you can ask a LLM to solve this problem for you.
Here is one prompt:
Do a for loop to find the mean TMIN and TMAX for the study period, using this code
```Python
#Subset to data in month 12 (December) and get the mean TMIN and TMAX in December throughout the study period
two_stations.loc[:,['TMIN','TMAX']].loc[two_stations.index.month == 12].mean()
```
For each iteration print the month name, TMIN, and TMAX in a table format.
This is the solution that I got from ChatGPT 3.5.
#Install tabulate if you are using it for the first time by uncommenting the pip install command
#pip install tabulate
# ChatGPT 3.5 Solution
#Import two modules
import calendar
from tabulate import tabulate
# Initialize a list to store the results
results = []
# Iterate over each month
for month in range(1, 13):
#Subset condition with datetime index is the month == 12 (December)
condition= two_stations.index.month == month
# Subset data for the current month and calculate mean TMIN and TMAX
monthly_data = two_stations.loc[:, ['TMIN', 'TMAX']].loc[condition,:]
mean_TMIN = monthly_data['TMIN'].mean()
mean_TMAX = monthly_data['TMAX'].mean()
# Get month name
month_name = calendar.month_name[month]
# Append the results to the list
results.append([month_name, round(mean_TMIN, 2), round(mean_TMAX, 2)])
# Print results in table format
print(tabulate(results, headers=["Month", "Mean TMIN", "Mean TMAX"], tablefmt="pretty"))
+-----------+-----------+-----------+
| Month | Mean TMIN | Mean TMAX |
+-----------+-----------+-----------+
| January | 56.1 | 76.36 |
| February | 60.26 | 81.19 |
| March | 62.72 | 84.81 |
| April | 66.59 | 87.55 |
| May | 69.44 | 89.94 |
| June | 74.18 | 90.94 |
| July | 76.18 | 92.62 |
| August | 76.21 | 92.82 |
| September | 74.6 | 90.66 |
| October | 70.92 | 87.29 |
| November | 64.87 | 81.77 |
| December | 58.58 | 77.2 |
+-----------+-----------+-----------+
A comprehensive example (advanced)#
Let us look at an example where we can apply many of the methods that we learned. Let use reslove the above problem without using loops. We can use something that we learned before like groupby in Section 4.10. Remember groupby is tool for grouping data based on some criteria, which can include time-related criteria but is not limited to time-series data.
Here is a solution strategy
Use something like
.index.monthto find the month number for each rowAdd the month number for each row as a new column, e.g., ‘month’
Select the columns ‘TMIN’, ‘TMAX’, ‘month’:
[['TMIN','TMAX', 'month']]or.loc[:, ['TMIN','TMAX','month']]Groupby by ‘month’:
.groupby('month')Apply
.mean()function
So far we have used the DataFrame as is without adding or removing a column to the DataFrame. Let us now add to two_stations a new column ‘month’. The value returned by df.index.month is used to obtain the data for this new column:
#Add new column 'month' with its values obtained from index
two_stations['month'] = two_stations.index.month
#Display new DataFrame
two_stations
| STATION | NAME | PRCP | TMAX | TMIN | AWND | month | |
|---|---|---|---|---|---|---|---|
| DATE | |||||||
| 2020-01-01 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.00 | 77.0 | 53.0 | 4.92 | 1 |
| 2020-01-02 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.00 | 84.0 | 57.0 | 7.61 | 1 |
| 2020-01-03 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.00 | 84.0 | 69.0 | 9.62 | 1 |
| 2020-01-04 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.15 | 83.0 | 64.0 | 10.51 | 1 |
| 2020-01-05 | USW00012894 | FORT MYERS SW FLORIDA REGIONAL AIRPORT, FL US | 0.00 | 68.0 | 49.0 | 7.16 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 2023-12-27 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 76.0 | 58.0 | 5.37 | 12 |
| 2023-12-28 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.35 | 69.0 | 57.0 | 4.03 | 12 |
| 2023-12-29 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 71.0 | 55.0 | 6.04 | 12 |
| 2023-12-30 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 67.0 | 51.0 | 5.14 | 12 |
| 2023-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 70.0 | 50.0 | NaN | 12 |
2922 rows × 7 columns
Select the columns that you want to apply groupby to. Then groupby month and the apply .mean().
# Select columns -> Groupby month -> Apply mean to find the mean for each month
two_stations.loc[:, ['TMIN','TMAX','month']].groupby('month').mean()
| TMIN | TMAX | |
|---|---|---|
| month | ||
| 1 | 56.100806 | 76.362903 |
| 2 | 60.261062 | 81.185841 |
| 3 | 62.721774 | 84.810484 |
| 4 | 66.591667 | 87.550000 |
| 5 | 69.435484 | 89.935484 |
| 6 | 74.175732 | 90.941667 |
| 7 | 76.177419 | 92.625000 |
| 8 | 76.213710 | 92.822581 |
| 9 | 74.599156 | 90.658228 |
| 10 | 70.923077 | 87.287449 |
| 11 | 64.870833 | 81.766667 |
| 12 | 58.584677 | 77.197581 |
In the above example, I solved the problem in five steps through adding the new column month for illustration purpose. You can only solve it in three steps without adding the new column month as follows:
# Select columns -> Groupby month -> Apply mean to find the mean for each month
two_stations.loc[:, ['TMIN','TMAX']].groupby(two_stations.index.month).mean()
| TMIN | TMAX | |
|---|---|---|
| DATE | ||
| 1 | 56.100806 | 76.362903 |
| 2 | 60.261062 | 81.185841 |
| 3 | 62.721774 | 84.810484 |
| 4 | 66.591667 | 87.550000 |
| 5 | 69.435484 | 89.935484 |
| 6 | 74.175732 | 90.941667 |
| 7 | 76.177419 | 92.625000 |
| 8 | 76.213710 | 92.822581 |
| 9 | 74.599156 | 90.658228 |
| 10 | 70.923077 | 87.287449 |
| 11 | 64.870833 | 81.766667 |
| 12 | 58.584677 | 77.197581 |
How can you customize your table to look like the table you got in the above example with loop. I asked ChatGPT 3.5, and here is what I got:
import calendar
# Select columns, group by month, and apply mean to find the mean for each month
monthly_means = two_stations.loc[:, ['TMIN', 'TMAX']].groupby(two_stations.index.month).mean()
# Map month numbers to month names
monthly_means.index = monthly_means.index.map(lambda x: calendar.month_name[x])
# Round mean values to two decimal points
monthly_means = monthly_means.round(2)
# Rename the columns
monthly_means = monthly_means.rename(columns={'TMIN': 'Mean TMIN', 'TMAX': 'Mean TMAX'})
# Print the resulting DataFrame
display(monthly_means)
| Mean TMIN | Mean TMAX | |
|---|---|---|
| DATE | ||
| January | 56.10 | 76.36 |
| February | 60.26 | 81.19 |
| March | 62.72 | 84.81 |
| April | 66.59 | 87.55 |
| May | 69.44 | 89.94 |
| June | 74.18 | 90.94 |
| July | 76.18 | 92.62 |
| August | 76.21 | 92.82 |
| September | 74.60 | 90.66 |
| October | 70.92 | 87.29 |
| November | 64.87 | 81.77 |
| December | 58.58 | 77.20 |
In the code above we learned everything expect for .map() and lambda function. You can ask your LLM to learn more about this. However, if you can understand that much, you have a very good understanding of Pandas and Python in general.
Note
Prompt engineering entails crafting precise prompts to guide a large language model (LLM) to generate desired outputs. Mastering prompt engineering enables effective utilization of LLMs across tasks from problem-solving to creative writing. Learn more with Real Python's tutorial on Prompt Engineering: A Practical Example.Prompt engineering involves crafting precise and effective prompts or instructions to guide a large language model (LLM) to generat the desired outputs. Learning prompt engineering, through providing clear guidance and constraints, will help you to effectively harness the capabilities of LLMs for various tasks from creative writing to problem-solving. To learn prompt engineering you can check for example Prompt Engineering: A Practical Example tutorial by Real Python.
4.15 Quick Plots of Your Data#
A good way to explore your data is by making a simple plot. Pandas contains its own .plot method; this allows us to plot Pandas series without needing matplotlib.
4.15.1 Line plot#
This is very simply:
df[columns_to_plot].plot(opitions_as_needed)
In this example, we plot the TMAX and TMIN series of our DataFrame with lin plot.
#Select data to plot: TMAX and TMIN
data_to_plot=['TMAX','TMIN']
#Plot method
one_station[data_to_plot].plot();
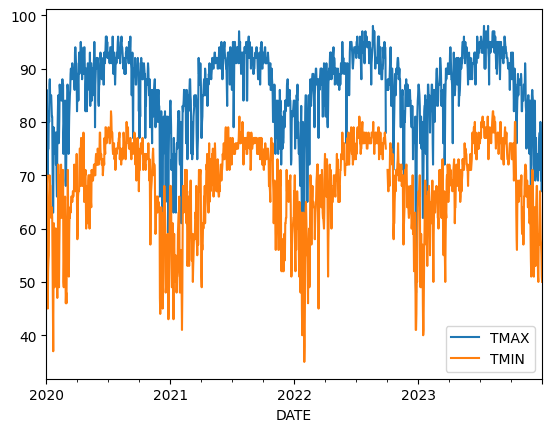
Note
Note when using.plot()in Pandas, appending a semicolon ; at the end of the statement suppresses the output of additional information such as '< Axes: xlabel='DATE'>' text that is displayed at the top of the plot.
4.15.2 Histogram plot#
In the previous example we called .plot(), which generated a single line plot. Line plots can be helpful for understanding some types of data, but there are other types of data that can be better understood with different plot types. For example, if you want to see the distribution of your data, you can better do this with a histogram plot.
Let us do something more advanced than the previous example to build on what we learned before. Let use say we want to see the TMAX distributions for years 2022 and 2023. That is tricky. Let us think about this step-by-step. First we need to create two new columns 2022_TMAX and 2023_TMAX, such that 2022_TMAX will contain TMAX data for 2022, and 2023_TMAX will contain TMAX data for 2023. Then we can plot the data of these two new columns.
We have learned how to do this before with Slicing and with Subsetting. Here is how to do this with Slicing
#Slicing data for 2022 and 2023 and adding it to the DataFrame
one_station['2022_TMAX'] = one_station.TMAX.loc['2022']
one_station['2023_TMAX'] = one_station.TMAX.loc['2023']
# Display updated DataFrame to show the two new columns '2022_TMAX' and '2023_TMAX'
one_station
| STATION | NAME | PRCP | TMAX | TMIN | AWND | 2022_TMAX | 2023_TMAX | |
|---|---|---|---|---|---|---|---|---|
| DATE | ||||||||
| 2020-01-01 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 78.0 | 54.0 | 4.70 | NaN | NaN |
| 2020-01-02 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 85.0 | 59.0 | 7.16 | NaN | NaN |
| 2020-01-03 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 86.0 | 70.0 | 8.28 | NaN | NaN |
| 2020-01-04 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.17 | 82.0 | 65.0 | 10.07 | NaN | NaN |
| 2020-01-05 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 70.0 | 50.0 | 8.95 | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2023-12-27 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 76.0 | 58.0 | 5.37 | NaN | 76.0 |
| 2023-12-28 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.35 | 69.0 | 57.0 | 4.03 | NaN | 69.0 |
| 2023-12-29 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 71.0 | 55.0 | 6.04 | NaN | 71.0 |
| 2023-12-30 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 67.0 | 51.0 | 5.14 | NaN | 67.0 |
| 2023-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 70.0 | 50.0 | NaN | NaN | 70.0 |
1461 rows × 8 columns
Let use delete these two columns and add them again with the subsetting method
# Drop the specified columns from the DataFrame
#one_station.drop(columns= ['2022_TMAX', '2023_TMAX'], inplace=True)
one_station
| STATION | NAME | PRCP | TMAX | TMIN | AWND | 2022_TMAX | 2023_TMAX | |
|---|---|---|---|---|---|---|---|---|
| DATE | ||||||||
| 2020-01-01 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 78.0 | 54.0 | 4.70 | NaN | NaN |
| 2020-01-02 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 85.0 | 59.0 | 7.16 | NaN | NaN |
| 2020-01-03 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 86.0 | 70.0 | 8.28 | NaN | NaN |
| 2020-01-04 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.17 | 82.0 | 65.0 | 10.07 | NaN | NaN |
| 2020-01-05 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 70.0 | 50.0 | 8.95 | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2023-12-27 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 76.0 | 58.0 | 5.37 | NaN | 76.0 |
| 2023-12-28 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.35 | 69.0 | 57.0 | 4.03 | NaN | 69.0 |
| 2023-12-29 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 71.0 | 55.0 | 6.04 | NaN | 71.0 |
| 2023-12-30 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 67.0 | 51.0 | 5.14 | NaN | 67.0 |
| 2023-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 70.0 | 50.0 | NaN | NaN | 70.0 |
1461 rows × 8 columns
Now add these two columns back using the subsetting method
#Subsetting 2022 and 2023 data and adding it to the DataFrame
one_station['2022_TMAX'] = one_station.TMAX.loc[one_station.index.year == 2022]
one_station['2023_TMAX'] = one_station.TMAX.loc[one_station.index.year == 2023]
# Display updated DataFrame to show the two new columns '2022_TMAX' and '2023_TMAX'
one_station
| STATION | NAME | PRCP | TMAX | TMIN | AWND | 2022_TMAX | 2023_TMAX | |
|---|---|---|---|---|---|---|---|---|
| DATE | ||||||||
| 2020-01-01 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 78.0 | 54.0 | 4.70 | NaN | NaN |
| 2020-01-02 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 85.0 | 59.0 | 7.16 | NaN | NaN |
| 2020-01-03 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 86.0 | 70.0 | 8.28 | NaN | NaN |
| 2020-01-04 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.17 | 82.0 | 65.0 | 10.07 | NaN | NaN |
| 2020-01-05 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 70.0 | 50.0 | 8.95 | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2023-12-27 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 76.0 | 58.0 | 5.37 | NaN | 76.0 |
| 2023-12-28 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.35 | 69.0 | 57.0 | 4.03 | NaN | 69.0 |
| 2023-12-29 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 71.0 | 55.0 | 6.04 | NaN | 71.0 |
| 2023-12-30 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 67.0 | 51.0 | 5.14 | NaN | 67.0 |
| 2023-12-31 | USW00012835 | FORT MYERS PAGE FIELD AIRPORT, FL US | 0.00 | 70.0 | 50.0 | NaN | NaN | 70.0 |
1461 rows × 8 columns
Now we have our data ready for plotting.
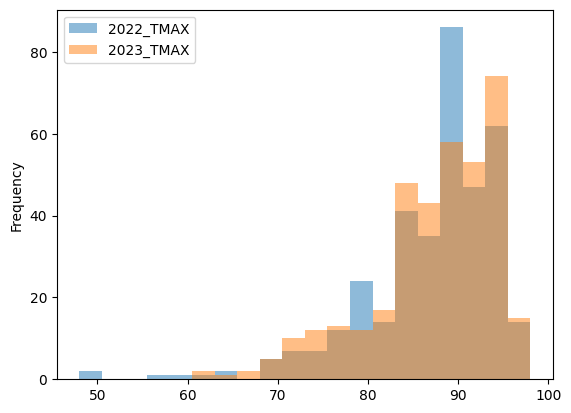
The code for plotting histogram data is slighlty differs from the code for line plot. After calling the .plot method, we call an additional method called .hist, which converts the plot into a histogram. Also, we are calling .hist with two additional opitional parameters. The first parameter alpha is for adjusting the transparency. For example, alpha=0.5 sets the transparency level of the plotted histogram to 50%. The parameter bins specifies the number of bins used to divide the range of the data into equal intervals for plotting the histogram.
#Select data to plot
data_to_plot=['2022_TMAX','2023_TMAX']
#Histogram method (alpha parameter for transparency)
one_station[data_to_plot].plot.hist(alpha=0.5, bins=20);
4.15.3 Box plot#
The histogram plot helped us to look differently at the data. It seems that the two datasets are from the same distribution. To even better understand this data, it may also be helpful to create a box plot. This can be done using the same code, with one change: we call the .box method instead of .hist.
#Select data to plot
data_to_plot=['2022_TMAX','2023_TMAX']
#Box method
one_station[data_to_plot].plot.box();
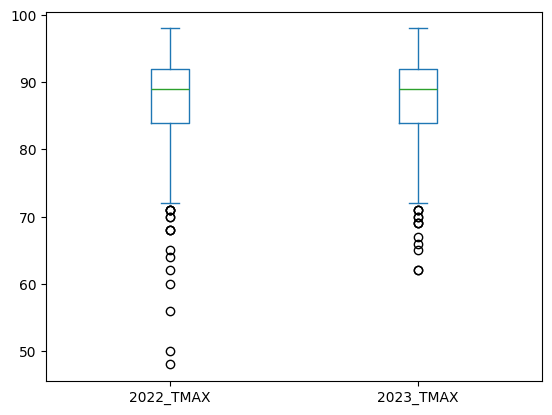
Just like the histogram plot, this box plot indicates no clear difference in the distributions. Using multiple types of plot in this way can be useful for verifying large datasets. The Pandas plotting methods are capable of creating many different types of plots. To see how to use the plotting methods to generate each type of plot, please review the Pandas plot documentation.
4.15.4 Customize your Plot#
The Pandas plotting methods are, in fact, wrappers for similar methods in matplotlib. This means that you can customize Pandas plots by including keyword arguments to the plotting methods. These keyword arguments, for the most part, are equivalent to their matplotlib counterparts.
#Plain plotting without customization
one_station[['TMAX','TMIN']].plot();
#Here are some customizations that you can do
one_station[['TMAX', 'TMIN']].plot(
color=['red', 'blue'], # Set different colors for TMAX and TMIN
linewidth=1, # Set the width of the lines to 1
xlabel='Date', # Set the label for the x-axis
ylabel='Temperature (deg F)', # Set the label for the y-axis
figsize=(12, 4), # Set the size of the figure to (8, 6) inches
title='Max and Min Temperature Over Time', # Add a title to the plot
grid=False, # Do not show gridlines on the plot
legend=True, # Show a legend
style=['-', '-'], # Set solid line for TMAX and TMIN
alpha=0.8, # Set the transparency of the lines to 0.8
xlim=('2020-01-01', '2024-01-01'), # Set the limits for the x-axis
ylim=(30, None), # Set the lower limit for the y-axis to 0
rot=0, # Rotate x-axis labels by 0 degrees
fontsize=12, # Set font size for labels
);
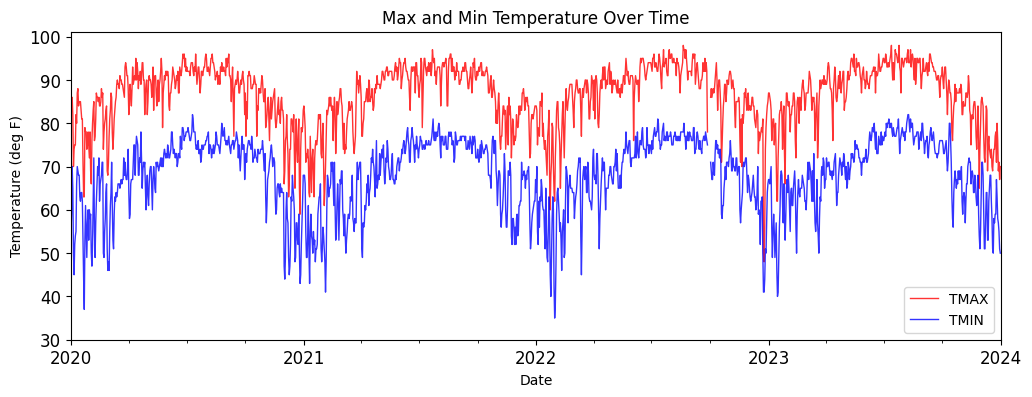
4.16 Applying operations to a DataFrame#
One of the most commonly used features in Pandas is the performing of calculations to multiple data values in a DataFrame simultaneously. Let’s first look at a a function that converts temperature values from degrees Fahrenheit to Celsius.
def fahrenheit_to_celsius(temp_ferh):
"""
Converts from degrees Fahrenheit to Celsius.
"""
return (temp_ferh - 32) * 5/9
#Test your function here be checking freezing point
fahrenheit_to_celsius(32)
0.0
Let us create a new DataFrame for temperature data and apply ferhenirt_to_celsius function to convert data from Ferhenirt to Celsius. Then add the new data as two new columns TMAX_C and TMIN_C. This can take this form:
df[new_columns] = my_function(original_columns)
Also, rename the original TMAX to TMAX_F and TMIN to TMIN_F. For renaming you can use the rename function:
df = df.rename(columns={'old_name1': 'new_name1', 'old_name2': 'new_name2'})
Here is how to do this:
# Create a new DataFrame for temp values TMAX and TMIN
temp=one_station[['TMAX','TMIN']].copy()
# Convert temp from F to C and save to new columns TMAX_C and TMIN_C
temp[['TMAX_C','TMIN_C']]= fahrenheit_to_celsius(temp)
#Change the name of TMAX to TMAX_F and TMIN to TMIN_F
temp = temp.rename(columns={'TMAX': 'TMAX_F', 'TMIN': 'TMIN_F'})
# Display new DataFrame
display(temp)
| TMAX_F | TMIN_F | TMAX_C | TMIN_C | |
|---|---|---|---|---|
| DATE | ||||
| 2020-01-01 | 78.0 | 54.0 | 25.555556 | 12.222222 |
| 2020-01-02 | 85.0 | 59.0 | 29.444444 | 15.000000 |
| 2020-01-03 | 86.0 | 70.0 | 30.000000 | 21.111111 |
| 2020-01-04 | 82.0 | 65.0 | 27.777778 | 18.333333 |
| 2020-01-05 | 70.0 | 50.0 | 21.111111 | 10.000000 |
| ... | ... | ... | ... | ... |
| 2023-12-27 | 76.0 | 58.0 | 24.444444 | 14.444444 |
| 2023-12-28 | 69.0 | 57.0 | 20.555556 | 13.888889 |
| 2023-12-29 | 71.0 | 55.0 | 21.666667 | 12.777778 |
| 2023-12-30 | 67.0 | 51.0 | 19.444444 | 10.555556 |
| 2023-12-31 | 70.0 | 50.0 | 21.111111 | 10.000000 |
1461 rows × 4 columns
Another way of doing this is to use .apply() such that
df[new_columns] = df[original_columns].apply(my_function)
Try it out:
# Create a new DataFrame for temp values TMAX and TMIN
temp=one_station[['TMAX','TMIN']].copy()
# Convert temp from F to C and save to new columns TMAX_C and TMIN_C
temp[['TMAX_C','TMIN_C']]= temp.apply(fahrenheit_to_celsius)
#Change the name of TMAX to TMAX_F and TMIN to TMIN_F
temp = temp.rename(columns={'TMAX': 'TMAX_F', 'TMIN': 'TMIN_F'})
# Display new DataFrame
display(temp)
| TMAX_F | TMIN_F | TMAX_C | TMIN_C | |
|---|---|---|---|---|
| DATE | ||||
| 2020-01-01 | 78.0 | 54.0 | 25.555556 | 12.222222 |
| 2020-01-02 | 85.0 | 59.0 | 29.444444 | 15.000000 |
| 2020-01-03 | 86.0 | 70.0 | 30.000000 | 21.111111 |
| 2020-01-04 | 82.0 | 65.0 | 27.777778 | 18.333333 |
| 2020-01-05 | 70.0 | 50.0 | 21.111111 | 10.000000 |
| ... | ... | ... | ... | ... |
| 2023-12-27 | 76.0 | 58.0 | 24.444444 | 14.444444 |
| 2023-12-28 | 69.0 | 57.0 | 20.555556 | 13.888889 |
| 2023-12-29 | 71.0 | 55.0 | 21.666667 | 12.777778 |
| 2023-12-30 | 67.0 | 51.0 | 19.444444 | 10.555556 |
| 2023-12-31 | 70.0 | 50.0 | 21.111111 | 10.000000 |
1461 rows × 4 columns
This is just the beginning. You can convert a Pandas DataFrame to numpy array for more advanced array operations. You can do this conversion using the method .values.
Check the type of your DataFrame.
type(temp)
pandas.core.frame.DataFrame
Now use the method temp.values and check the type again.
type(temp.values)
numpy.ndarray
We will learn later learn Numpy, whihc handles multi-dimensional arrays with extensive collection of mathematical functions, facilitating high-performance numerical computations.
4.17 Iterating over rows (opitional)#
We can apply a function row at a time using a for loop and the iterrows() method. This will allow us to iterate row by row using iterrows() in a for loop to repeat a given process for each row in a Pandas DataFrame. Please note that iterating over rows is a rather inefficient approach, but this is your last resort when the other methods cannot do what you need.
Let’s start with a simple for loop that goes through each row in our DataFrame
# Create a new DataFrame for temp values TMAX and TMIN
temp=one_station.loc['2023-12-29':'2023-12-31', ['TMAX','TMIN']].copy()
# Iterate over the rows
for idx, row in temp.iterrows():
# Print the index value
display(idx)
# Print the row
display(row['TMAX'])
display(row['TMIN'])
break #Break is used to show only the first iteration of the for loop for testing purpose
Timestamp('2023-12-29 00:00:00')
np.float64(71.0)
np.float64(55.0)
Now for each value let use apply our fahrenheit_to_celsius function.
# Create a new DataFrame for temp values TMAX and TMIN
temp=one_station[['TMAX','TMIN']].copy()
# Iterate over the rows
for idx, row in temp.iterrows():
# Convert TMAX from Fahrenheit to Celsius
temp.loc[idx, 'TMAX_C'] = fahrenheit_to_celsius(row['TMAX'])
# Convert TMIN from Fahrenheit to Celsius
temp.loc[idx, 'TMIN_C'] = fahrenheit_to_celsius(row['TMIN'])
#Change the name of TMAX to TMAX_F and TMIN to TMIN_F
temp = temp.rename(columns={'TMAX': 'TMAX_F', 'TMIN': 'TMIN_F'})
# Display the resulting DataFrame with temperatures converted to Celsius
display(temp)
| TMAX_F | TMIN_F | TMAX_C | TMIN_C | |
|---|---|---|---|---|
| DATE | ||||
| 2020-01-01 | 78.0 | 54.0 | 25.555556 | 12.222222 |
| 2020-01-02 | 85.0 | 59.0 | 29.444444 | 15.000000 |
| 2020-01-03 | 86.0 | 70.0 | 30.000000 | 21.111111 |
| 2020-01-04 | 82.0 | 65.0 | 27.777778 | 18.333333 |
| 2020-01-05 | 70.0 | 50.0 | 21.111111 | 10.000000 |
| ... | ... | ... | ... | ... |
| 2023-12-27 | 76.0 | 58.0 | 24.444444 | 14.444444 |
| 2023-12-28 | 69.0 | 57.0 | 20.555556 | 13.888889 |
| 2023-12-29 | 71.0 | 55.0 | 21.666667 | 12.777778 |
| 2023-12-30 | 67.0 | 51.0 | 19.444444 | 10.555556 |
| 2023-12-31 | 70.0 | 50.0 | 21.111111 | 10.000000 |
1461 rows × 4 columns
4.18 Save and load your DataFrame#
In this final example, we demonstrate the use of the to_csv method to save a DataFrame as a .csv file. This example also demonstrates the read_csv method, which reads .csv files into Pandas DataFrames.
4.18.1 Save a DataFrame as .csv file#
The to_csv method saves a DataFrame as a .csv file as
df.to_csv('file_path/file_name.csv')
Try to to save your temp DataFrame to ‘temp_data.csv’
# Save your temp data in F and C to a CSV file 'temp_data.csv'
temp.to_csv('temp_data.csv')
4.18.2 Read a .csv files into DataFrames#
We want to
read the file as new DataFrame called
df_temp,set our first column as our index column,
and change the format of our index to datetime format.
Let us break it down part by part.
First, you can use the read_csv method reads .csv files into Pandas DataFrames
df_name= pd.read_csv('file_path/file_name.csv', index_col = 0, parse_dates = True )
Second, set the the first column which contain datetime data as our index using:
index_col = 0
which specifies that the first column of the CSV file should be used as the index of the DataFrame. If you want for example to use your third column as the index of your DataFrame, you can do index_col = 2 and so on.
Third, parse any date-like columns as datetime objects using
parse_dates = True
which instructs Pandas to attempt to parse any datetime columns including index in the CSV file as datetime objects.
Here is how to do this:
# Read file as a new DataFrame 'df_temp', and set first column as index with datetime format
df_temp= pd.read_csv('temp_data.csv', index_col = 0, parse_dates = True)
#Display your new DataFrame
display(df_temp)
| TMAX_F | TMIN_F | TMAX_C | TMIN_C | |
|---|---|---|---|---|
| DATE | ||||
| 2020-01-01 | 78.0 | 54.0 | 25.555556 | 12.222222 |
| 2020-01-02 | 85.0 | 59.0 | 29.444444 | 15.000000 |
| 2020-01-03 | 86.0 | 70.0 | 30.000000 | 21.111111 |
| 2020-01-04 | 82.0 | 65.0 | 27.777778 | 18.333333 |
| 2020-01-05 | 70.0 | 50.0 | 21.111111 | 10.000000 |
| ... | ... | ... | ... | ... |
| 2023-12-27 | 76.0 | 58.0 | 24.444444 | 14.444444 |
| 2023-12-28 | 69.0 | 57.0 | 20.555556 | 13.888889 |
| 2023-12-29 | 71.0 | 55.0 | 21.666667 | 12.777778 |
| 2023-12-30 | 67.0 | 51.0 | 19.444444 | 10.555556 |
| 2023-12-31 | 70.0 | 50.0 | 21.111111 | 10.000000 |
1461 rows × 4 columns
What we did not learn so far is how to create a DataFrame from a given data rather than reading it from a file. You can learn this on your own. Ask a LLM for example and guide yourself through the learning process.
Summary#
Pandas is a very powerful tool for working with tabular (i.e., spreadsheet-style) data
There are multiple ways of subsetting your Pandas dataframe or series
Pandas allows you to refer to subsets of data by label, which generally makes code more readable and more robust
Pandas can be helpful for exploratory data analysis, including plotting and basic statistics
One can apply calculations to Pandas dataframes and save the output via
csvfiles
What’s Next?#
To learn Pandas, you do not need to read more, but to practice more. Start working on your homework. When encountering challenges, refer back to this notebook and seek assistance from a LLM. If the LLM provided a new method that you do not understand, ask for explanation. When you write a code that does not work, ask for debugging. Practice as much as you can to learn this powerful data analysis tool.